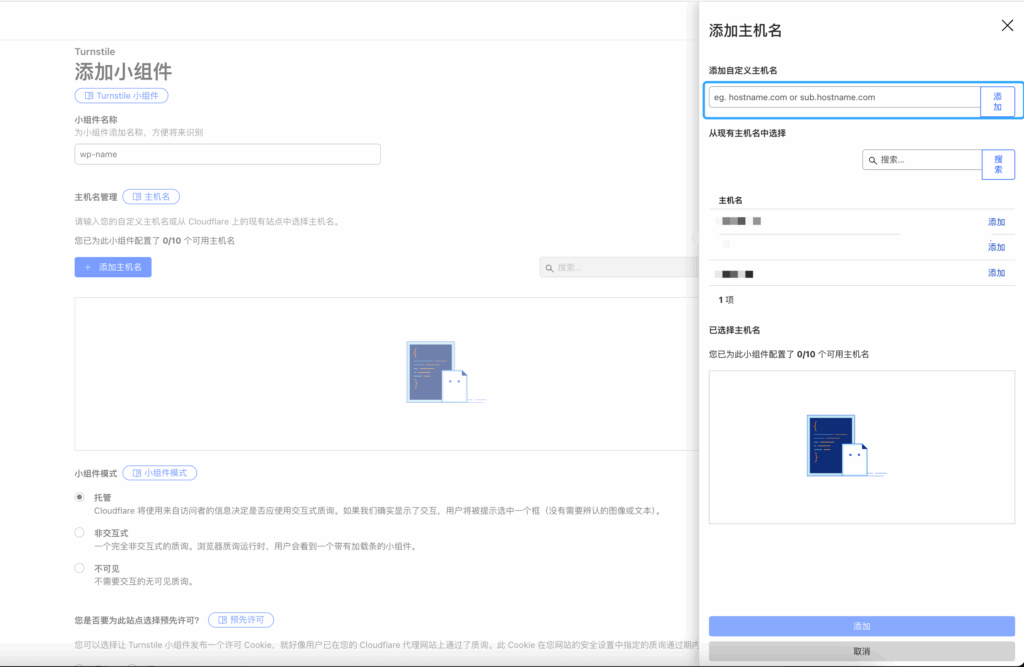
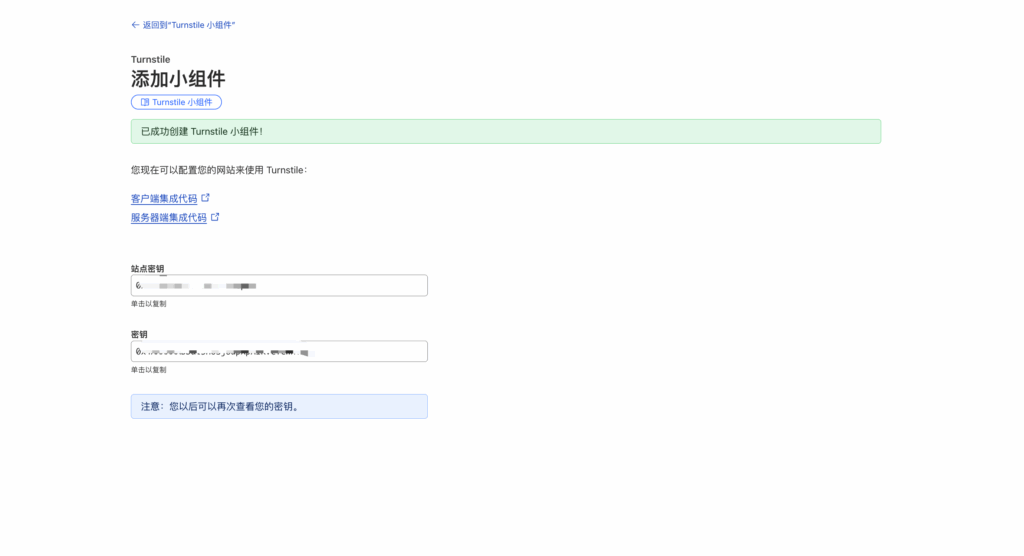
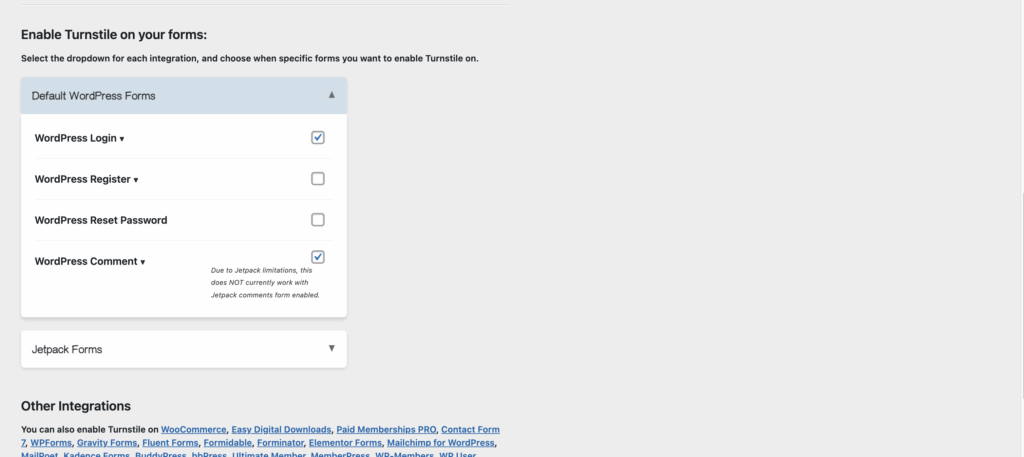
The Model Context Protocol (MCP) is an open protocol that enables seamless integration between LLM applications and external data sources and tools. Whether you’re building an AI-powered IDE, enhancing a chat interface, or creating custom AI workflows, MCP provides a standardized way to connect LLMs with the context they need.
模型上下文协议(MCP)是一个开放协议,旨在实现LLM应用与外部数据源和工具之间的无缝集成。无论您是在构建AI驱动的集成开发环境(IDE)、增强聊天界面,还是创建自定义的AI工作流,MCP都提供了一种标准化的方式,将LLM与所需的上下文连接起来。
As AI assistants gain mainstream adoption, the industry has invested heavily in model capabilities, achieving rapid advances in reasoning and quality. Yet even the most sophisticated models are constrained by their isolation from data—trapped behind information silos and legacy systems. Every new data source requires its own custom implementation, making truly connected systems difficult to scale.
随着AI助手的广泛采用,业界在模型能力上进行了大量投资,取得了快速的推理和质量进展。然而,即便是最复杂的模型也受到与数据隔离的限制——被困在信息孤岛和遗留系统中。每个新的数据源都需要定制的实现,使得真正连接的系统难以扩展。
MCP addresses this challenge. It provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol. The result is a simpler, more reliable way to give AI systems access to the data they need.
MCP解决了这一挑战。它提供了一种通用的开放标准,用于将AI系统与数据源连接,通过一个单一协议取代了碎片化的集成。结果是为AI系统提供所需数据的更简单、更可靠的方式。
Model Context Protocol
The Model Context Protocol is an open standard that enables developers to build secure, two-way connections between their data sources and AI-powered tools. The architecture is straightforward: developers can either expose their data through MCP servers or build AI applications (MCP clients) that connect to these servers.
模型上下文协议是一个开放标准,使开发者能够在其数据源和AI驱动的工具之间建立安全的双向连接。其架构非常简单:开发者可以通过MCP服务器暴露其数据,或构建连接到这些服务器的AI应用(MCP客户端)。
Today, we’re introducing three major components of the Model Context Protocol for developers:
- The Model Context Protocol specification and SDKs (模型上下文协议规范和SDK)
- Local MCP server support in the Claude Desktop apps (Claude桌面应用中的本地MCP服务器支持)
- An open-source repository of MCP servers (MCP服务器的开源代码库)
Claude 3.5 Sonnet is adept at quickly building MCP server implementations, making it easy for organizations and individuals to rapidly connect their most important datasets with a range of AI-powered tools. To help developers start exploring, we’re sharing pre-built MCP servers for popular enterprise systems like Google Drive, Slack, GitHub, Git, Postgres, and Puppeteer.
Claude 3.5 Sonnet擅长快速构建MCP服务器实现,使组织和个人能够迅速将其最重要的数据集与各种AI驱动的工具连接起来。为了帮助开发者快速入门,我们提供了适用于Google Drive、Slack、GitHub、Git、Postgres和Puppeteer等流行企业系统的预构建MCP服务器。
Early adopters like Block and Apollo have integrated MCP into their systems, while development tools companies including Zed, Replit, Codeium, and Sourcegraph are working with MCP to enhance their platforms—enabling AI agents to better retrieve relevant information to further understand the context around a coding task and produce more nuanced and functional code with fewer attempts.
像Block和Apollo这样的早期采用者已将MCP集成到其系统中,而开发工具公司如Zed、Replit、Codeium和Sourcegraph也正在与MCP合作,增强他们的平台——使AI代理能够更好地检索相关信息,更好地理解编程任务的上下文,并生成更细致、功能更强大的代码,减少尝试次数。
“At Block, open source is more than a development model—it’s the foundation of our work and a commitment to creating technology that drives meaningful change and serves as a public good for all,” said Dhanji R. Prasanna, Chief Technology Officer at Block. “Open technologies like the Model Context Protocol are the bridges that connect AI to real-world applications, ensuring innovation is accessible, transparent, and rooted in collaboration. We are excited to partner on a protocol and use it to build agentic systems, which remove the burden of the mechanical so people can focus on the creative.”
Block的首席技术官Dhanji R. Prasanna表示:“在Block,开源不仅仅是开发模型——它是我们工作的基础,是创建推动有意义变化的技术、服务公共利益的承诺。像模型上下文协议这样的开源技术,是将AI与现实世界应用连接起来的桥梁,确保创新能够得到访问、透明,并且根植于合作。我们很高兴能合作制定这个协议,并用它构建代理系统,去除机械的负担,让人们专注于创意。”
Instead of maintaining separate connectors for each data source, developers can now build against a standard protocol. As the ecosystem matures, AI systems will maintain context as they move between different tools and datasets, replacing today’s fragmented integrations with a more sustainable architecture.
开发者现在可以在标准协议的基础上进行开发,而不必为每个数据源维护单独的连接器。随着生态系统的成熟,AI系统将能够在不同工具和数据集之间保持上下文,取代当前的碎片化集成,形成一种更可持续的架构。
Getting started
Developers can start building and testing MCP connectors today. Existing Claude for Work customers can begin testing MCP servers locally, connecting Claude to internal systems and datasets. We’ll soon provide developer toolkits for deploying remote production MCP servers that can serve your entire Claude for Work organization.
开发者可以立即开始构建和测试MCP连接器。现有的Claude for Work客户可以开始本地测试MCP服务器,将Claude连接到内部系统和数据集。我们很快将提供开发工具包,用于部署远程生产MCP服务器,服务整个Claude for Work组织。
To start building:
- Install pre-built MCP servers through the Claude Desktop app(通过Claude桌面应用安装预构建的MCP服务器)
- Follow our quickstart guide to build your first MCP server (按照我们的快速入门指南构建第一个MCP服务器)
- Contribute to our open-source repositories of connectors and implementations(为我们的开源连接器和实现代码库做出贡献)
An open community
We’re committed to building MCP as a collaborative, open-source project and ecosystem, and we’re eager to hear your feedback. Whether you’re an AI tool developer, an enterprise looking to leverage existing data, or an early adopter exploring the frontier, we invite you to build the future of context-aware AI together.
我们致力于将MCP构建为一个协作的开源项目和生态系统,并期待听取您的反馈。无论您是AI工具开发者、希望利用现有数据的企业,还是正在探索前沿的早期采用者,我们邀请您一起构建上下文感知AI的未来。

 首页真的很赞,几乎无广告,看着很清爽。
首页真的很赞,几乎无广告,看着很清爽。